It's data pipelines that provide the information your AI applications need. But these pipelines have to do more than just deliver data — they also need to be robust and resilient in the long term, making sure your applications remain fit-for-purpose or even become more capable over time.
Achieving this is all about adopting the right approach to data processing, as well as the best practices that make pipeline development easier and more streamlined. Read on to discover more.
Processing structured and unstructured data
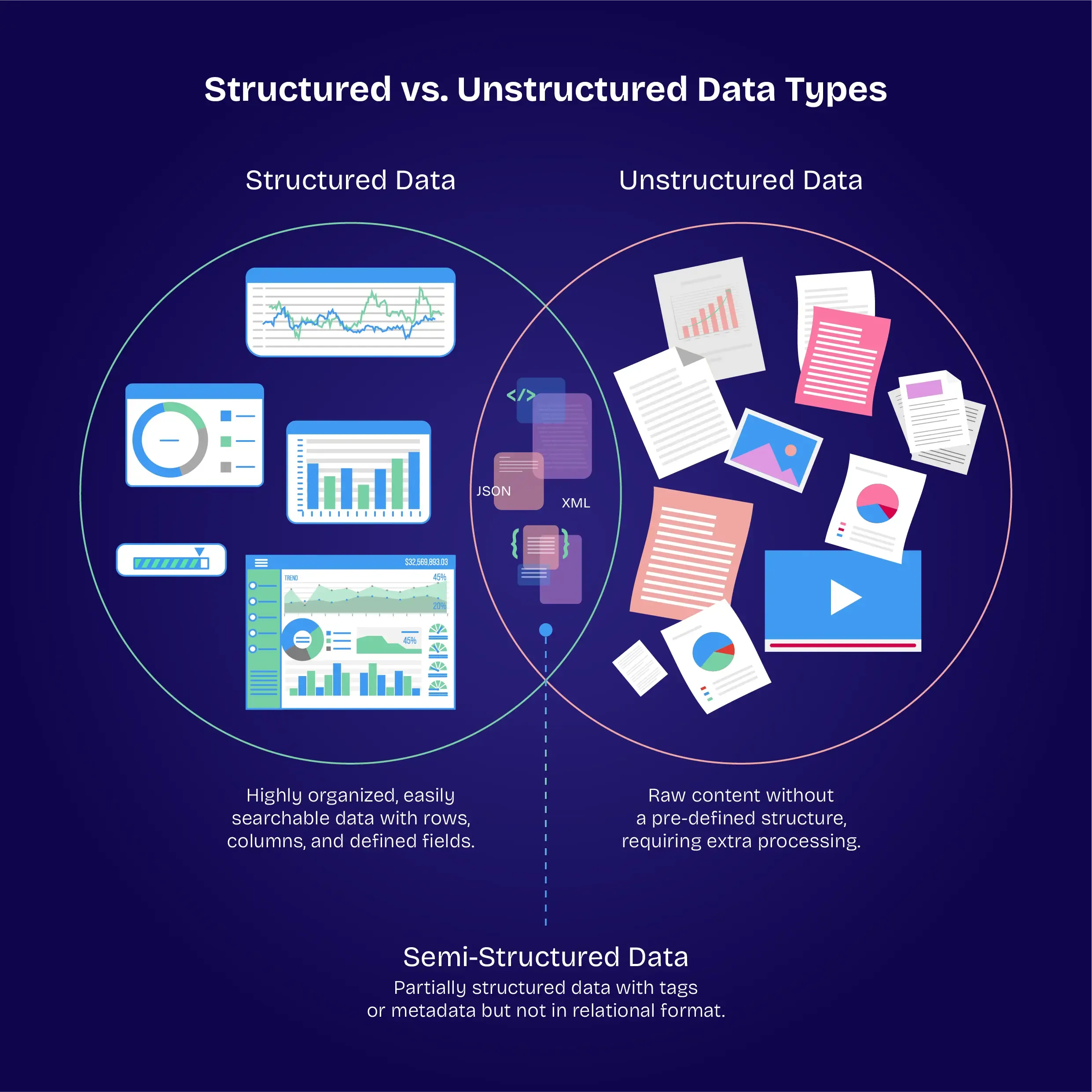
AI applications rely on data, but data can come in different forms. Typically, these forms are broken down into two main categories — structured and unstructured data. A robust data pipeline will need to consume and process both types of data, but this can bring challenges.
Structured data
Structured data is easier to process, simply because of the way it is arranged. This data is provided in tables and features categories and labels that make management easy. As the data is already ordered, the pipeline simply needs to carry out a straightforward ETL process — extract, transform, load.
Unstructured data
Unstructured data lacks the organisation of structured data. This essentially adds an extra step in processing, as the data needs to be organised and arranged before it is processed. Solutions may need to apply labels, sort the data into categories, and translate data into different formats before the processing can begin.
Semi-structured data
There may be a third category also. JSON logs and XML data, for example, feature a degree of structure but are not strictly ordered. This can be challenging for data pipelines, as the solution will need to understand the methodology used in organising the data and then process it accordingly.
Across all three categories, data quality is key. Processing solutions need to be able to deliver high-quality inputs to the AI application. The old adage "garbage in equals garbage out" is very true with AI, so you need to know what type of data you are dealing with and make sure this is processed correctly in the pipeline.
Best practices in data pipeline management and integration
The right best practices can make sure your data pipeline is delivering high-quality information to your AI application.
Establish clear pipeline stages
Adopting a modular approach makes your pipeline far easier to test and debug. For example:
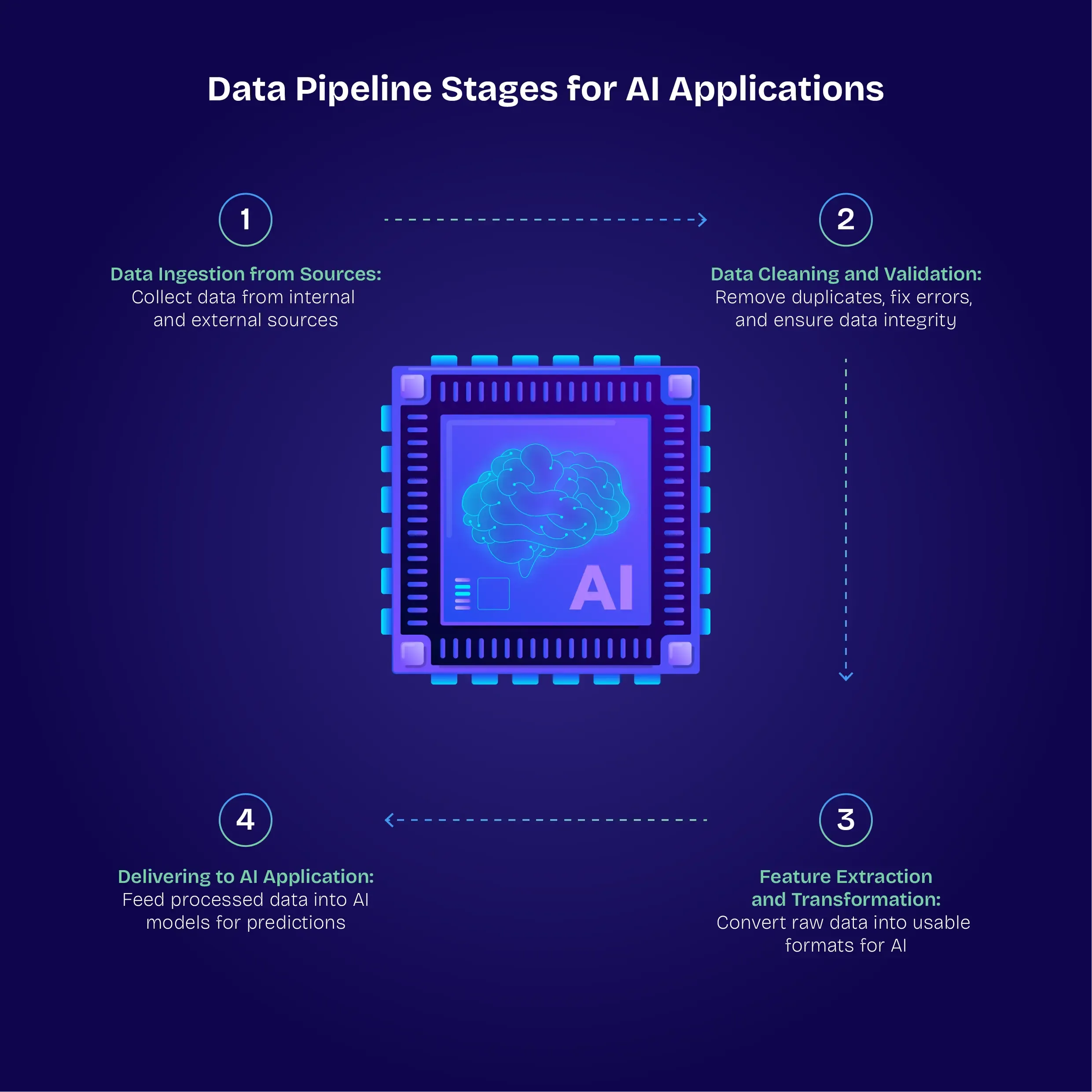
- Stage 1 – Data ingestion from sources
- Stage 2 – Data cleaning and validation
- Stage 3 – Featured extraction and transformation
- Stage 4 – Delivering to AI application
Automate and schedule pipelines
There are plenty of solutions out there to help you manage and run your pipeline. Apache Airflow, AWS Step Functions, and Azure Data Factory can all take some of the strain out of pipeline operation while also reducing human error.
Monitor data quality and drift
Drift is a real concern in the world of machine learning and AI. Just because the output was what you expected the first time does not necessarily mean this is going to be the case across future iterations. Systematic monitoring according to schema validation, statistical integrity, and record volume can help you spot if anything seems "off," which may suggest your data has drifted and your pipeline needs a tweak.
Keep on top of versioning and lineage
Everything comes in different iterations — the source dataset, the data processing code, and the application itself will develop and evolve over time. So you'll end up with multiple versions of each. It's important to keep track of which combination of versions contributed to which outcome. Tools like Pachyderm can help you manage version data.
Manage scalability and efficiency
Data volumes have been increasing for years, and that trend is showing no sign of slowing down. As these volumes grow, pipelines need to grow in scale too. Distributed processing can help here, and big data frameworks such as Spark and Hadoop will assist you in processing large batches of data. Caching intermediate results and executing incremental pipeline updates can speed up your workflow.
Integrate with machine learning operations
The data pipeline exists within the wider machine learning operations (MLOps) eco-system. This means it is a good idea to integrate data pipelines with model training and deployment pipelines, utilising automation to trigger seamless action across the broader environment. Pipeline-as-code solutions can unify the entire system.
Prioritise security and access control
If you're handling data, you'll need to adhere to data protection regulations. And if you're working in AI, then you're definitely handling data. With this in mind, work to secure data in transit and at rest using encryption and implement strict controls on who can access the data. Stay on top of changes in data protection regulation and remain compliant at all times.
Enterprises operating under strict regulations — such as HIPAA healthcare frameworks and GDPR in Europe — need to demonstrate exactly how, when, and by whom data is accessed. This can be achieved through robust key management, encryption in transit (using TLS), and storage encryption (AES-256).
Beyond basic encryption, consider implementing an Identity and Access Management (IAM) solution providing fine-grained, role-based permissions. Regular security audits and compliance checks are also critical here, as they not only prevent unauthorised data exposure but also create an auditable trail. This trial ensures accountability and transparency, satisfying both internal governance policies and external regulatory requirements.
Demonstrate ROI and measurable benefits
For enterprise leadership, robust data pipelines translate directly to ROI. Streamlined ingestion and automated transformations can cut data preparation time by up to 40%. In turn, this frees up your teams to focus on higher-value tasks like model optimisation.
Likewise, consistent error checking and data validation reduce the risk of compliance breaches, avoiding potential fines and reputational damage — improvements that directly impact the bottom line.
Provide an implementation roadmap
Your teams need to know how pipelines will be implemented and what the end goal is. To achieve this, you'll need to outline a roadmap they can follow.
A practical roadmap might look like this:
- Identify Data Sources — Differentiate between ERP system and IoT sensor data, and classify them as structured, unstructured, or semi-structured.
- Define Pipeline Stages — Attach clear roles to each stage, from ingestion, cleaning, and transformation to validation.
- Select Orchestration Tools — Use Apache Airflow or Azure Data Factory and integrate the solution with your tech stack.
- Implement Version Control and Monitoring — Use these processes to flag anomalies, manage data drift, and track lineage.
- Evaluate Scalability and Security — Assess these needs upfront so that growth doesn’t compromise performance or compliance.
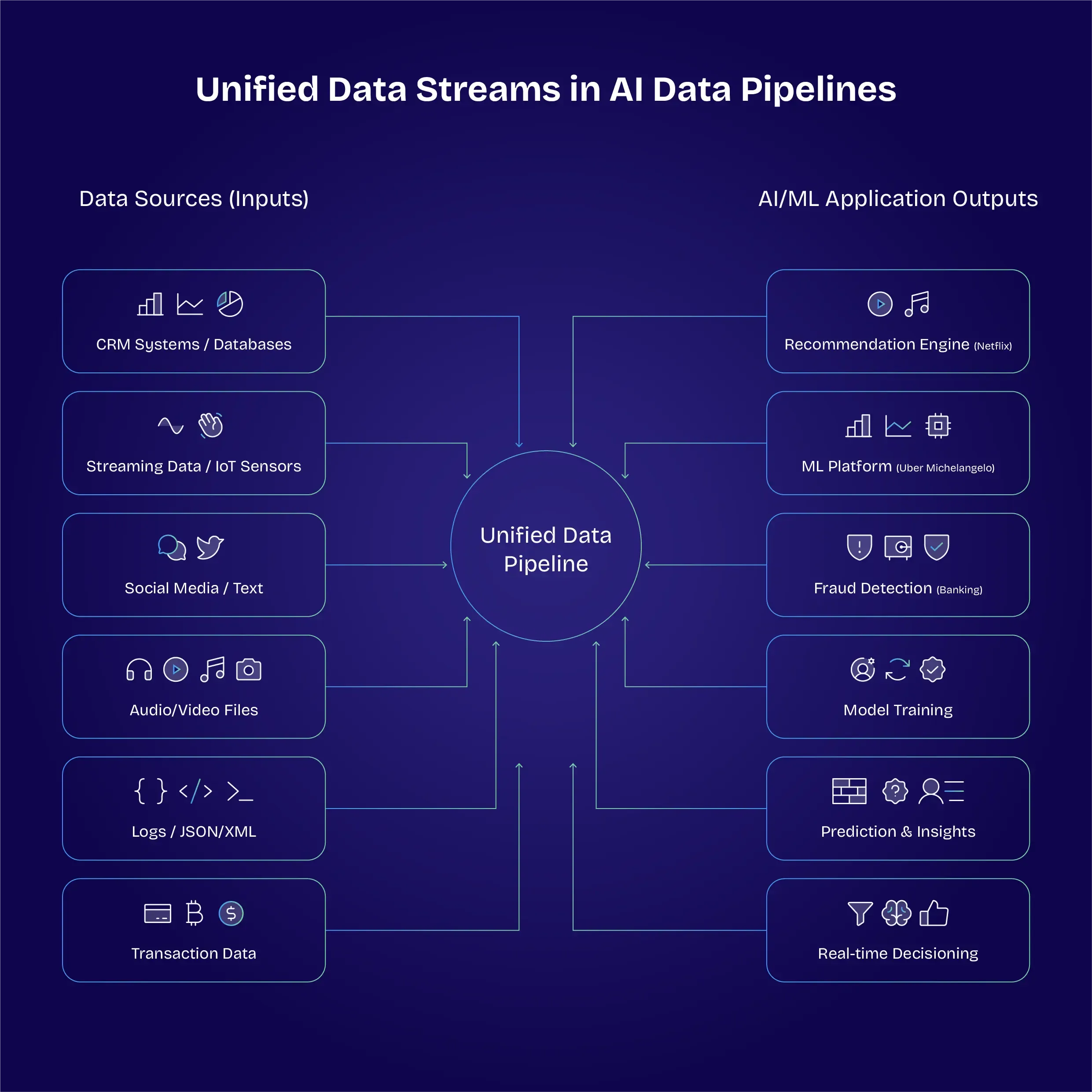
Why robust data pipelines are so important: Case Studies
Why are robust data pipelines so vital? These case studies provide real-world examples to support this:
Netflix — Personal recommendations
Netflix relies on sophisticated data pipelines to deliver recommendations to views. Users report that Netflix's algorithms are more engaging and more accurate than many of its competitors, and this simply would not be possible without a robust and resilient stream of data.
Uber — Michelangelo platform
Uber has invested heavily in developing the Michelangelo platform, an end-to-end solution bringing together multiple aspects of machine learning. Rather than depending on standalone pipelines for individual projects, Uber now benefits from a standardised environment for model development and deployment.
Banking — Fraud detection
Machine learning is used right across the banking industry to spot potential instances of fraud. By integrating credit card data, transaction metadata, and customer profiles, fraud detection teams built a streaming data pipeline with an extremely high success rate. Fraudulent charges are spotted automatically, with low false-positive rates — thanks to the pipeline's resilience.
Data pipelines support the future of AI
AI is only as good as the data pipeline feeding it. These pipelines not only deliver data but also clean, prepare, scale, and organise data before it reaches the AI-driven application. As we expect more and more from AI applications and as data volumes increase, these pipelines are only going to grow more important.
As we look ahead, we can see a shift approaching. If enterprises want to stay competitive, then robust, future-proof data architecture is no longer going to be a "nice to have" — it will be a strategic imperative.
This is why we recommend evaluating your current data pipeline — and preparing for the next phase of implementation — with new solutions and new capabilities.
To get a pipeline audit or technology gap analysis, reach out to our team. Let us help you turn your data into a real competitive advantage.