






















Is your AI model achieving what it should? Is it producing errors, reinforcing bias, or causing unintended harm? And how do you ensure it keeps improving?
While this might seem like rather a lot of questions to kick us off here, they all boil down to the same basic aim: create and deploy an AI model that is making a positive difference to your operations and to society as a whole.
To make this happen, we've outlined three best practices.
1. Choose the right metrics to measure performance. 2. Implement continuous monitoring and feedback. 3. Prioritise AI responsibility.
Read on to explore these in more detail.
Choose your metrics according to task type
There is an almost unlimited array of different metrics you can apply to your AI model. While this can be overwhelming, you can narrow down your options according to specific tasks.
Classification metrics
For classification, consider measuring the following:
- Accuracy – The percentage of total predictions that turned out to be correct
- Precision – The percentage of positive predictions that turned out to be correct
- Recall – The percentage of actual positive cases identified by the model
- F1 Score – A harmonised score combining precision and recall. Where p is the precision score and r is the recall score, the F1 score = 2 / ( ¹⁄p + ¹⁄r ).
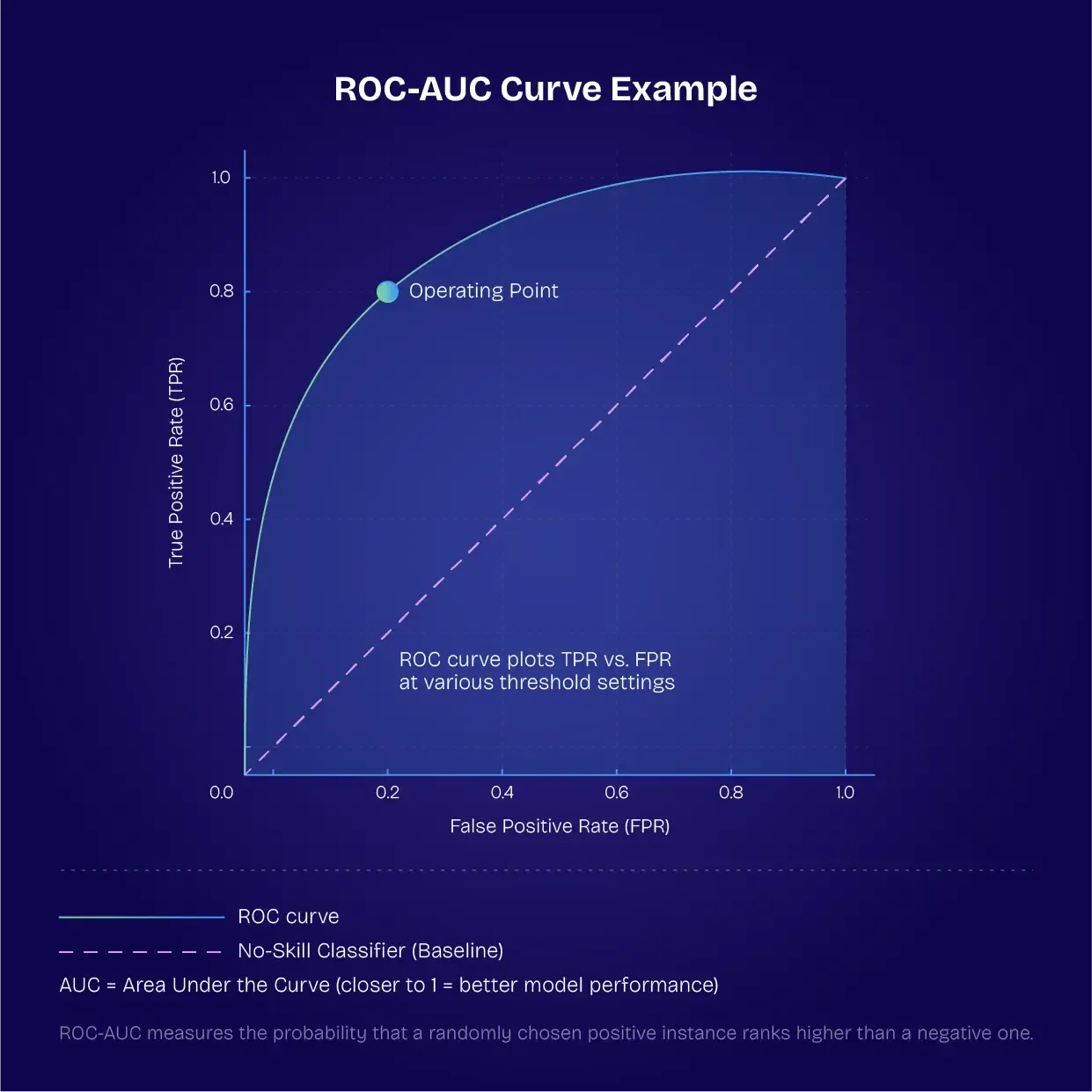
- Area Under the Receiver Operating Characteristic Curve (ROC-AUC) – The probability that a randomly selected positive classification will rank higher than a randomly selected negative.
Regression metrics
To measure regression, look at the following metrics:
- Mean squared error (MSE) – The square of the average difference between the predicted value and the actual value
- Root mean squared error (RMSE) – The square root of the MSE to give you an output in the same units as your input variable
- Mean absolute error (MAE) – The average magnitude of prediction errors
- Coefficient of determination (R2) – How variation in one variable is influenced by another variable, showing you how closely your data adheres to the regression model
Ranking and recommendation metrics
The following metrics can be applied to ranking and recommendation tasks:
- Mean Average Precision (MAP) – The average level of precision for object detection and information retrieval tasks
- Normalised Discounted Cumulative Gain (NDCG) – An aggregated metric taking into account the relevance of recommendations and their rank or position in a list
- Hit Rate@K – The proportion of recommendations that are relevant to the user making a query
NLP generation metrics
For natural language processing tasks, consider these metrics:
- Bilingual evaluation understudy (BLEU) score – How closely a machine translation adheres to a human translation
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE) score – Similar to the BLEU score, but used for evaluating summarised text
- Perplexity – How accurately a language model can predict the next word in an ordered sequence
Clustering and segmentation metrics
These two metrics are useful for clustering and segmentation tasks:
- Silhouette score – A metric to measure how results are clustered together
- Adjusted Rand Index (ARI) – A measure of how similar two different sections of a dataset are to one another
Fairness and robustness metrics
Fairness and robustness can be measured using the following metrics:
- Demographic parity difference – How membership of designated groups influences machine predictions
- Equal opportunity – Measuring disparities in the likelihood of a positive outcome among members of different groups
Set up continuous monitoring and feedback loops
It's not enough simply to build and deploy an AI model. You need to be continuously monitoring its operation, building feedback loops that show you how the model is performing in the real world. This includes the following:
Tracking the prediction quality over time
Data characteristics have a habit of changing, which results in "drift" – the degradation of AI model performance over time. Continually tracking the quality of AI predictions can defend against this. By regularly revisiting data pipelines and checking them for quality, you are ensuring that your model is fed with consistent and reliable data. Applying data governance policies prevents issues associated with corrupt or outdated data.
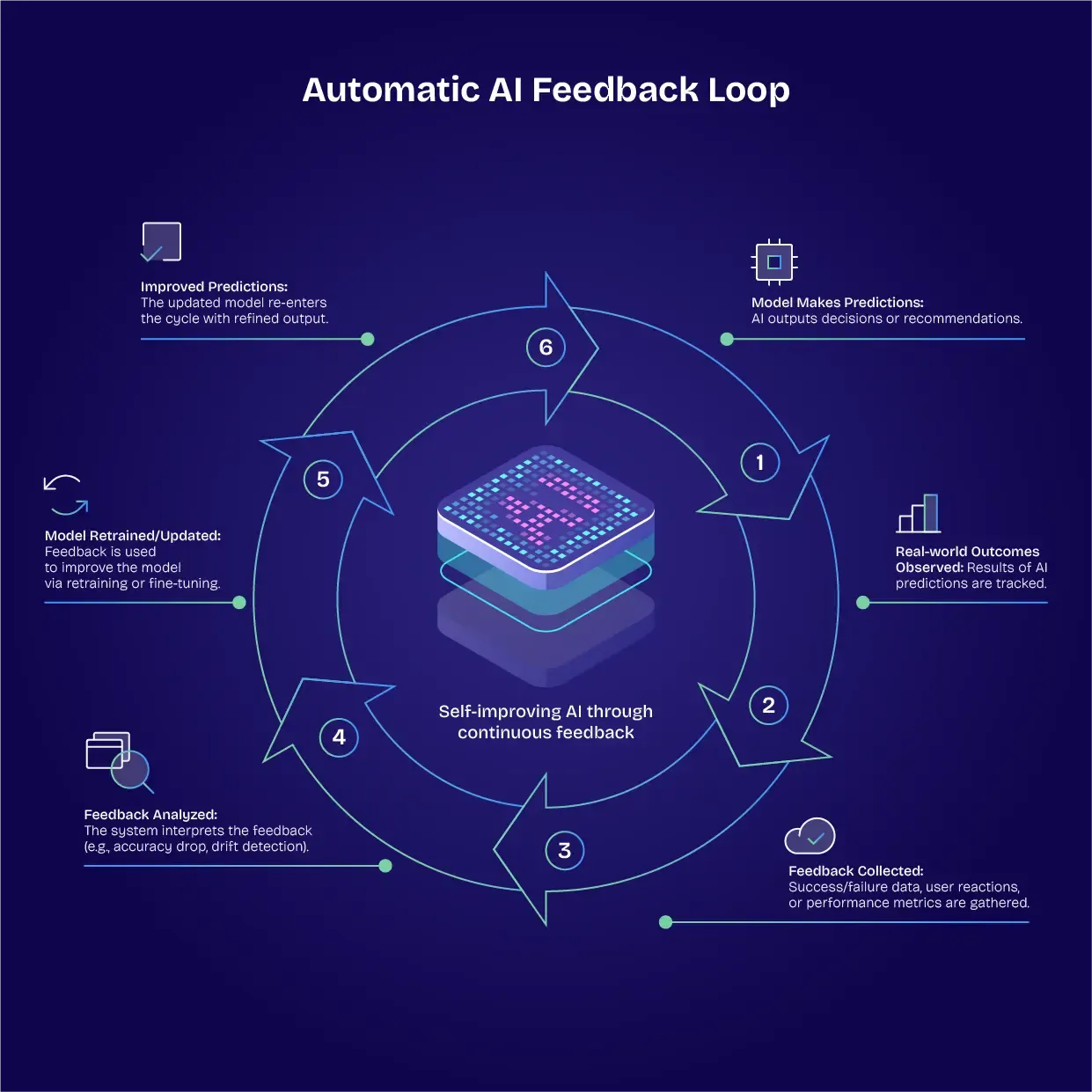
Building automatic feedback loops
One of the most astounding aspects of AI models is their ability to gather feedback and make changes automatically. Training the model to identify and collect feedback, and then to relay this back to the training pipeline, helps to make AI models self-sustaining. A virtuous cycle is created, where AI systems observe their own behaviours and outcomes.
Utilising A/B testing and iteration
While the results of AI can be revolutionary, some things don't change. The A/B testing method, used in software development for years, is one of those things. Making incremental changes, comparing the outcomes, and then developing new iterations based on this is an effective way to continually improve AI models.
Monitoring off-metric changes
Not all output changes will be measurable according to your metrics. You may begin to see new outputs emerging that you hadn't accounted for, which may be an indication of poor model health. Staying aware of these off-metric changes is critical.
Prioritise AI responsibility
We can define responsibility in different ways, according to ethical and legal frameworks, social standards, and performance benchmarks. True AI responsibility, however, involves all of these different aspects. Here's how you can prioritise this.
Conducting bias and fairness checks
We've looked at metrics you can use to measure bias and fairness, but you need to be looking at the outcomes too. If you begin to see a drift in positive outcomes across different demographic groups, this could suggest bias.
Auditing logs for traceability
AI systems are inherently traceable, as they can be set to log every prediction and action. Don't forget about these logs – audit them regularly to support accountability.
Using explainability tools
Tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) demonstrate how inputs influence model outputs. This helps you to ensure that decision-making remains transparent.
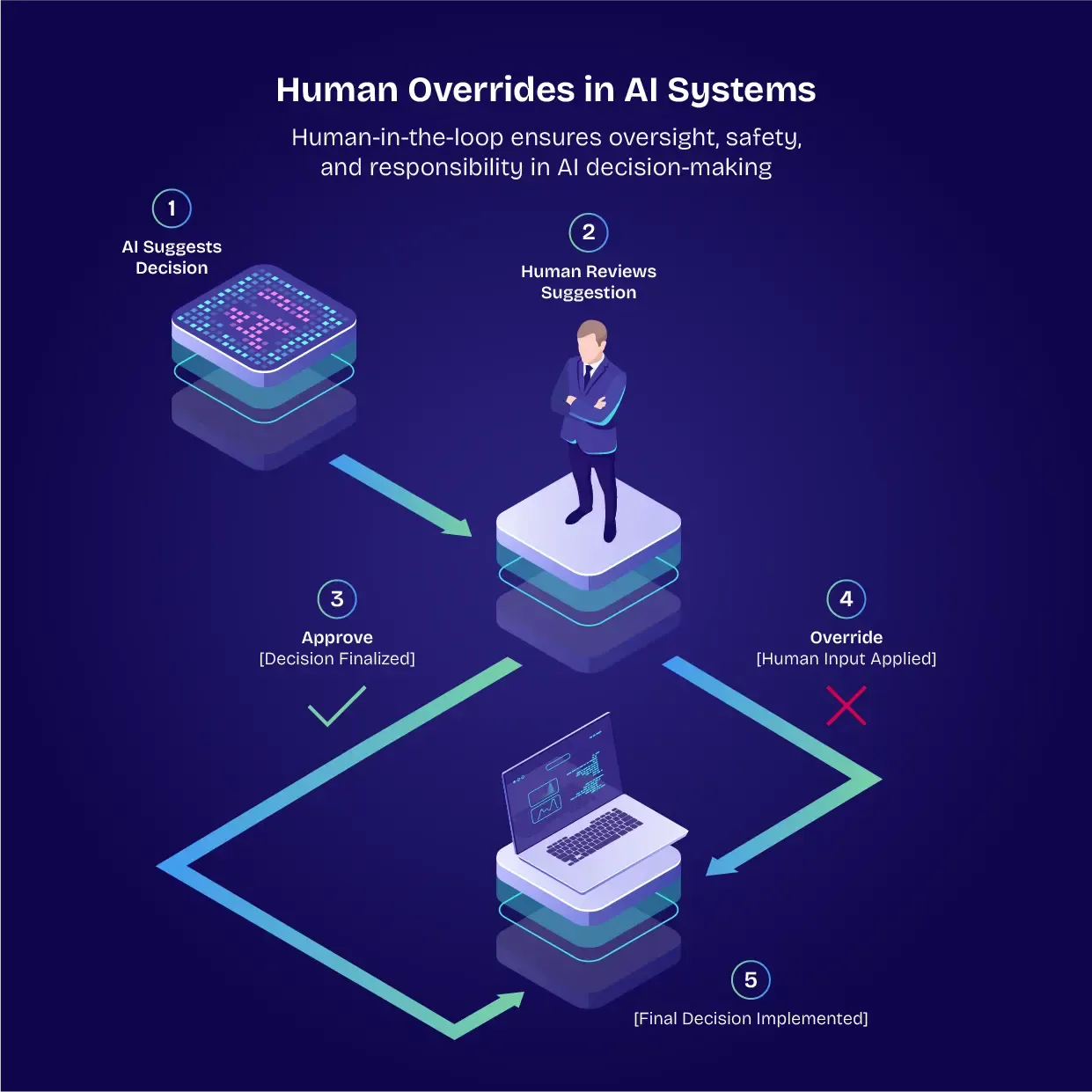
Implementing human overrides
'Human in the loop' is a big part of AI model deployment. Your human teams need to be able to override AI models, ensuring a reliable safety net. AI systems can also flag predictions for human review.
Carrying out regular reviews
Systematically reviewing the performance of the AI model, checking for unintended harm and negative outcomes, is vital to responsible deployment.
Monitoring compliance
Compliance is always changing and evolving. You'll need to make sure your AI model is in line with the latest regulations.
In conclusion: AI Is never 'set and forget'
We can't simply set and forget our AI models. As we've seen above, these things are not uniform, and their outputs are not absolute. Like living organisms, they can perform at their peak and they can get sick. It's up to us to make sure that we are continually monitoring the health and fitness-for-purpose of the AI models we deploy.
Basically, we need to adopt a qualified trust approach to AI deployment. We can put our faith in the power of these AI models, but we must assess, monitor, verify, and improve them – on an ongoing basis. This is the way to ensure that AI models benefit our society rather than doing unintended harm.